
人类演示是机器人掌握现实操作技能的核心途径,却一直被人机身体差异的问题 所困扰。 外观、肢体运动结构的天生不同,让机器人很难直接模仿人类的动作,尤其是需要全身协调的移动操控任务, 缺乏 全局的环境感知, 也 难以实现 跨身体的动作迁移,规模化学习更是无从谈起。
近日, 斯坦福大学与丰田研究所的联合团队研发的HoMMI框架,首次实现了机器人完全从无机器人参与的人类演示中, 学习 复杂的全身移动操控技能。

这套方案在UMI框架基础上新增自我中心感知能力,通过重构视觉与动作的 表征 形式、搭配贴合物理约束的全身控制器, 解决 了人机间的视觉偏差和运动学差异,让机器人能顺利完成融合双手配合、长距离导航、主动环境感知的长时程移动操控任务,为移动操控的规模化学习找到了 一条全新的思路。
PART 01
只用三部iPhone采集数据,HoMMI 如何实现跨体化操控?
HoMMI是一套覆盖数据采集、跨体化手眼策略设计、机器人全身控制的完整框架。

数据采集环节
团队将双手机械臂UMI框架轻量化、便携化改造,用三部iPhone搭建采集系统:两部装在夹爪,一部佩戴于演示者头部,借助苹果ARKit多设备协作能力建立统一全局坐标系。三部手机以60Hz频率同步记录RGB视频、深度图、6自由度位姿和夹爪宽度,生成的多模态轨迹数据可直接用于动作策略学习。该设备直观便携,能提供视觉和触觉反馈,避免VR设备采集时的运动眩晕,可在多样化真实环境中规模化采集数据。
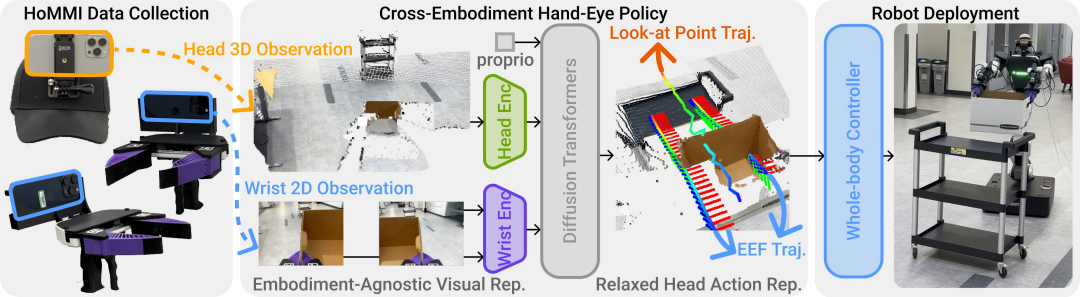
研究团队通过一套简易直观的数据采集接口、一套采用与身体形态无关的视觉表征及轻量化头部动作表征的跨具身策略设计,以及一套通过全身运动实现手眼跟踪并严格遵循物理约束的全身控制器,实现从人类演示中学习全身移动操控技能。
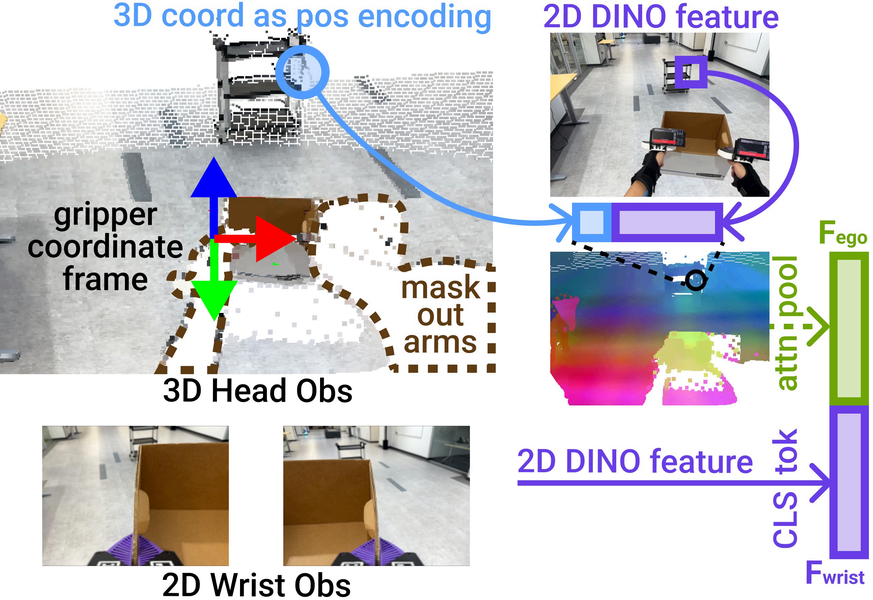
与身体形态无关的视觉表征
跨体化手眼策略是HoMMI解决人机身体差异的核心,团队从视觉 表征 、头部动作 表征 、空间参考系三个维度重构传统视觉运动策略。视觉层面,未直接输入头部RGB图像,而是将自我中心观测信息升级至3D空间,构建与身体形态无关的视觉 表征 :从深度信息提取点云图,分块下采样后为每个图像块提取DINO-v3 ViT特征,再与对应3D点正弦编码拼接,绑定外观特征与3D几何信息,提升对头部姿态和身高变化的适应性;同时将点云图转换至夹爪坐标系,屏蔽人类手臂等与身体形态相关的观测信息,减少外观不匹配干扰。
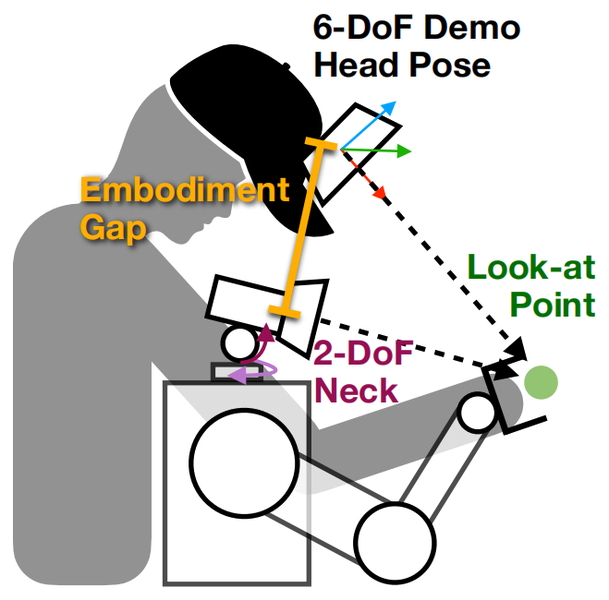
注视点动作表征
运动学层面,团队放弃照搬人类6自由度头部姿态的传统方式,提出3D注视点头部动作 表征 方法,将机器人头部运动控制转化为对3D空间注视点的控制,保留人类主动感知核心意图 的同时,也能 适配机器人运动学约束。训练时,注视点由相机中心光线与场景点云图交点计算;实际运行时,头部控制器根据注视点生成物理可行的头部朝向,适配仅2自由度颈部的标准移动机器人。
HoMMI以夹爪为所有观测和动作的中心参考系,将夹爪位姿、头部点云图和3D注视点全部转换至左夹爪坐标系,避免自我中心坐标系随头部运动和身体差异偏移,降低跨身体形态的信息不匹配问题。跨体化手眼策略基于扩散策略搭建,以2步短观测历史为依据,预测32步动作序列,融合手腕2D视觉特征、头部3D视觉 表征 和本体感受信息,输出双手夹爪位姿、3D注视点和夹爪宽度,实现精准手眼协调动作预测。
PART 02
跨体迁移总失败?HoMMI 这套全身控制器到底解决了什么?
策略仅输出笛卡尔空间末端执行器轨迹与头部注视点,需 要 依托专用全身控制器,将抽象指令转化为流畅稳定的全身协调动作,这也是HoMMI落地真实机器人 的 关键。
团队基于Mink搭建微分全身逆运动学求解器,核心通过带约束的二次规划,将笛卡尔空间动作目标转化为机器人关节速度与基座运动指令。求解器设计多层成本函数满足差异化控制需求:将双手6自由度轨迹跟踪设为核心成本项,保障机器人操控精度;加入标称姿态正则化,让机器人动作贴合人类运动习惯;增加当前姿态正则化,避免动作突发大幅变动,保证运动平滑性;增设重心约束项,使机器人上身体重始终稳定落于移动基座,从根 源上 保障运动稳定性。
求解器同步设置多项硬性物理约束,涵盖关节配置边界、关节与基座速度限制、自碰撞规避、躯干直立约束,杜绝机器人执行危险或无法实现的动作。针对策略低频率输出与机器人高频率控制的适配需求,控制器对策略输出目标指令做时间插值处理,位置采用线性插值,姿态采用球面线性插值,消除运动抖动,让整体动作连续流畅。
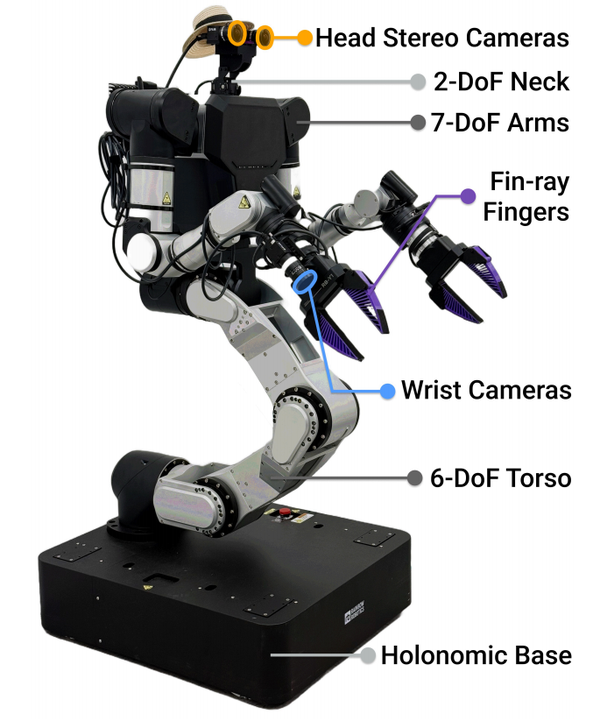
HoMMI 机器人硬件平台
硬件层面,团队基于Rainbow Robotics RB-Y1搭建双手机械臂移动操控平台,搭载7自由度双臂、6自由度躯干、2自由度颈部,基座采用全向移动结构;颈部装配工业级广角立体相机,腕部配备与采集设备同规格相机,夹爪替换为与UMI采集设备一致的鳍状手指,硬件端完全对齐数据采集与机器人部署的感知、执行组件,压缩跨身体形态迁移误差。
团队同步搭建异步策略推理架构,拆分感知、策略推理、全身控制三个独立环节:独立策略服务器负责接收带时间戳的观测信息并完成推理,实时执行桥接模块专项处理传感器信息时间对齐、过期动作过滤、目标指令时间同步。该架构规避了推理延迟导致的机器人动作卡顿问题,同时补偿传感器与推理延迟,保障指令执行精准度。
PART 03
90%成功率!HoMMI破解机器人长时程全身移动操控难题
团队在洗衣、递送、铺桌布三项长时程全身移动操控真实任务中测试HoMMI,设置腕部仅感知、简单添加头部RGB、头部仅感知、关闭主动颈部控制四种传统方案为对照,从跨体化迁移、双手/全身协调、长距离导航和主动感知四个维度验证其性能。

洗衣任务要求机器人完成靠近桌子、双手抓取布料、主动寻找收纳箱、导航至收纳箱并放入布料,核心考验双手协调、全身移动和主动感知能力。
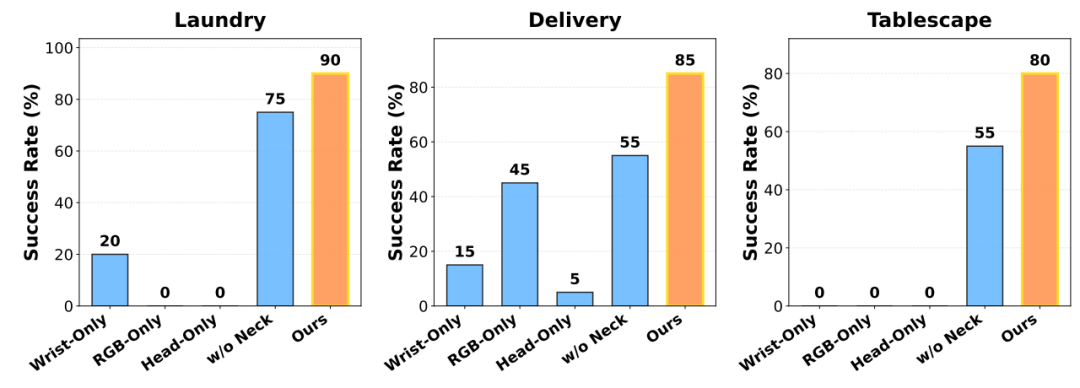
HoMMI成功率90%,可灵活导航并主动转动头部定位收纳箱,失败原因仅为布料抓取不牢固;四款对照方案表现极差:腕部仅感知、简单添加头部RGB、头部仅感知方案成功率均为0,关闭主动颈部控制方案成功率仅75%(布料放置偏差大)。

递送任务在6×6米空间进行,要求机器人双手托举盒子、寻找手推车、长距离导航并平稳放置盒子,核心考验长距离导航、双手协调和主动感知能力。HoMMI成功率85%,可实时修正导航偏差,失败原因仅为长距离导航后微小对位偏差;对照方案中,腕部仅感知成功率15%(频繁找错方向),简单添加头部RGB成功率45%(无法转向找手推车),头部仅感知成功率5%(盒子频繁碰撞),关闭主动颈部控制成功率55%(盒子放置滑落)。

铺桌布任务要求机器人靠近桌子、抓取垫子边缘、展开并平整铺设垫子,核心考验双手精准协调和全身配合能力。HoMMI成功率80%,具备任务恢复能力,失败原因仅为偶尔抓取位置偏差;对照方案中,腕部仅感知、简单添加头部RGB、头部仅感知方案成功率均为0,关闭主动颈部控制方案成功率55%(抓取失败无法恢复)。
实测表明:腕部局部接触信息与头部全局场景认知是完成复杂操控的必要条件;与身体形态无关的3D视觉及头部动作 表征 是解决人机差异的核心,简单添加头部RGB会因形态不匹配导致失败;主动头部控制可维持观测有效性,关闭后会显著降低成功率。
PART 04
结语与未来:
HoMMI打破移动操控机器人对遥操作数据的依赖,首次实现从纯人类演示到真实机器人全身移动操控的直接迁移。其轻量化数据采集系统、跨体化手眼策略及贴合物理约束的全身控制器,构成移动操控规模化学习的可落地、可推广完整框架。
此外, HoMMI的跨体化表征设计,可为拟人机器人、工业机械臂等各类机器人的模仿学习提供参考。未来随着感知方式丰富、记忆模块融入及硬件协同设计推进,机器人有望通过简单观察模仿,快速掌握复杂现实操作技能,实现真实场景落地应用。
论文链接:
https://hommi-robot.github.io/files/hommi_paper.pdf
项目地址:
https://hommi-robot.github.io/



