
从谷歌DeepMind的RT系列模型,到开源社区爆火的GR00T、Pi0,再到国内科技巨头与机器人企业接连发布的VLA大模型, 短短两年时间,几乎所有行业人士都在谈论模型 。
这种热闹程度,很容易让人联想到早年互联网接连涌现的门户网站。但目前来看,尽管各家都有自己的招牌与门面,可是底层的连接与流转,却远未畅通。
模型能力有多强已经成为老生常谈,但少有人追问,支撑这些模型走向物理世界的“工程地基”,是否已经牢固。
研究者们开始频繁遭遇同一个困境:花三个月训出的模型,在仿真环境里表现完美,一上真机就“手脚发抖”;换个数据集要重写整套数据处理脚本;想把视觉编码器从DINOv2换成SigLIP,发现代码耦合到几乎要推倒重来。
模型能力的边际收益正在递减, 工程化的系统性断裂却愈发刺眼 ,逐渐成为整个行业向前发展的桎梏。这种断裂体现在 数据格式碎片化 、 代码架构高耦合 以及 仿真到真机的迁移鸿沟三个层面。
这三重断裂叠加,形成了一个怪圈:模型越强,工程瓶颈越突出。因为更强的模型意味着更多的数据需求、更复杂的架构尝试、更高的部署期待,而每一条都将现有的工程支撑能力推向极限,愈显捉襟见肘。 这种系统性断裂不仅死死卡住了VLA技术规模化落地的咽喉,也让无数开发者在面对繁杂适配工作与陡峭学习曲线时感到无从下手。
入门,同样困难重重。
基于对上述行业现状的准确把握,国内头部的具身智能企业 逐际动力,正式发布并全面开源了FluxVLA Engine这个面向具身智能科研创新、应用开发与全场景落地的标准化工程底座 。

其并非又一个VLA大模型,也不是一个简单的模型集成平台。它想做的事情更基础,也更难短期见效: 为整个VLA应用链路提供一套标准化工程底座。
就像电网之于电器,公路之于车辆。
PART 01
从工具思维到基建思维:FluxVLA Engine的底层逻辑
面对上述的系统性断裂,行业的本能反应是“做一个更好的工具”。数据处理太乱?写一套新的数据加载器。代码耦合太重?重构一下模块划分。仿真到真机不稳定?调一调控制参数。
这些努力有价值,但往往治标不治本。因为 断裂的本质不在于某个环节做得不够好,而在于整个链路缺乏统一的标准和接口 。
就像一座城市,每栋楼都用自己的发电机组,插头规格却互不兼容,空有电力而无法使用。不是楼的设计有问题,而是整个城市缺一套统一的电网标准。
FluxVLA Engine的设计逻辑,正是 从“工具思维”转向“基建思维” 。
它的核心设计理念可以概括为四个词: 统一配置、标准接口、模块解耦、加速部署 。这四个词 层层递进 ,构成了一个 完整的工程逻辑 。
统一配置是地基。FluxVLA Engine采用“All-in-one”配置机制,通过单一配置文件,统一管理数据、模型、训练、评测、推理与部署参数。
这意味着从数据处理到真机部署的全流程,用户不再需要维护多套脚本和配置,即可切换各类模型。这种设计,不仅大幅降低了开发与维护的成本,更从根源上避免了多环节参数不匹配带来的错误与性能损耗,让整个研发流程的可控性与稳定性,实现了质的提升。
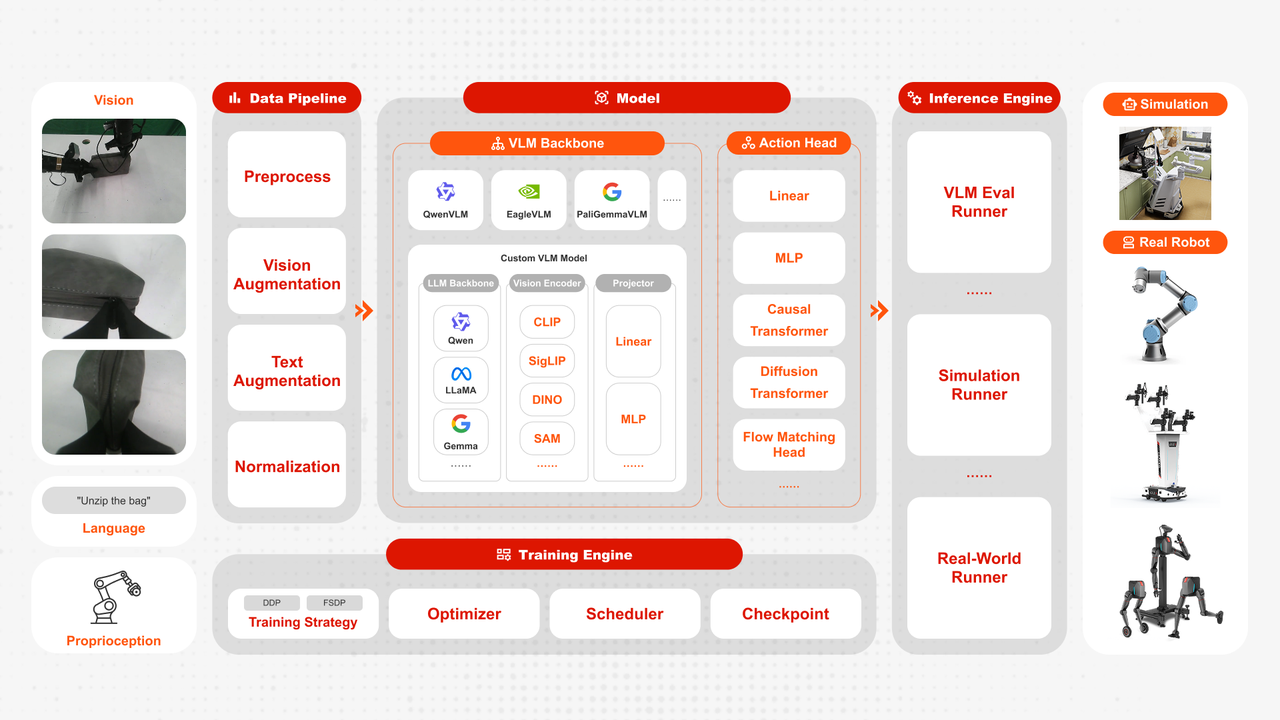
标准接口与模块解耦是身体。FluxVLA Engine的核心设计是将海量数据处理、模型调用与部署相关模块解耦,并以标准化接口贯穿全流程,包括视觉编码器、语言主干、动作头、数据加载器、仿真适配器、硬件驱动层等。
这就意味着,无论是更换数据集、替换模型主干,还是从仿真环境切换到真机硬件,所有模块的输入输出格式与接口规范,都能保持完全一致,无需进行任何重复的适配工作。
更重要的是,这种设计解锁了一个全新的可能性。开发者可以在同一套框架下,像更换零部件一样进行取舍。通过系统性对比不同视觉编码器、不同语言模型组合所带来的性能增益,进行优化搭配,从而以以极低的成本,快速构建出最适合自身工称的定制化模型架构。
这种极致的解耦与标准化,让开发者能够把最宝贵的精力,投入到算法创新、场景优化这些真正有价值的工作上。
加速部署是结果。FluxVLA Engine可以将训练完成后的模型直接导出,并通过标准化流程部署到真实机器人平台。可以说,这个工程底座真正实现了“开箱即用的真机部署”,打通了从算法验证到物理执行的闭环,破解了仿真到真机的迁移鸿沟。
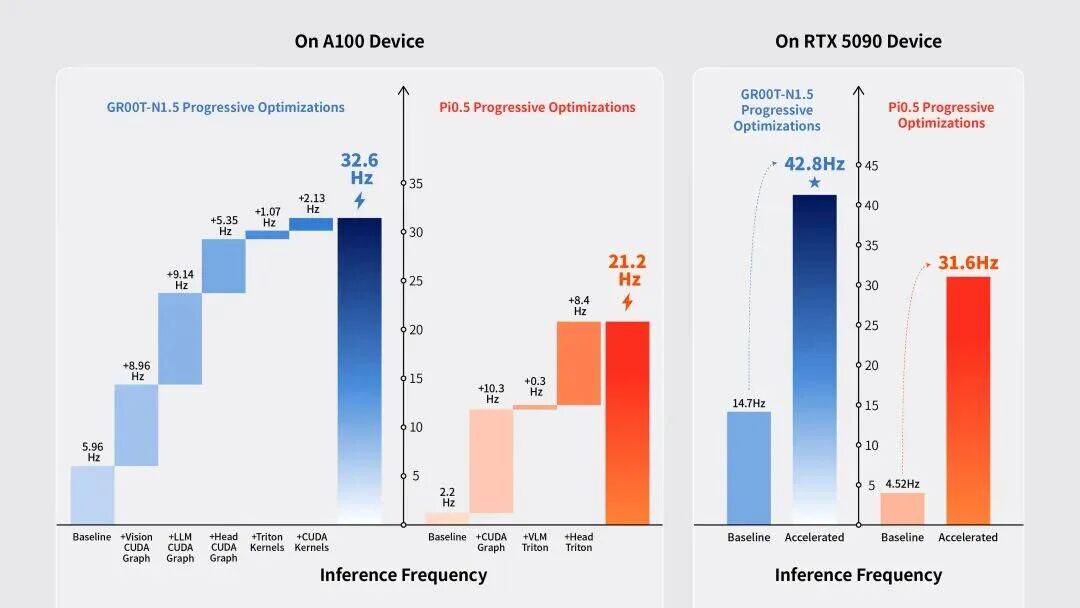
此外,为了确保真机部署后的稳定运行,FluxVLA通过底层推理引擎优化和算子融合,以及集成实时控制(RTC)等最新的轨迹平滑方法,从系统方面进行了优化。
这种设计哲学的改变,让FluxVLA Engine不再是一个“让你更好用VLA模型”的工具,而是 一个“让VLA模型能被更好地构建和部署”的底座 。区别微妙但根本:前者最终服务的可能只是某个环节、某个特定场景下的优化问题,后者 旨在服务的是整个开发链路——从数据到模型,从仿真到真机 。
PART 02
不是又一个平台:FluxVLA Engine的差异化定位
行业里不缺VLA相关的工具和平台。NVIDIA有Isaac Lab和GR00T工作流,斯坦福有OpenVLA的生态体系,各家机器人公司也陆续开源了自己的训练框架。FluxVLA Engine和它们有什么区别?
最直观的对比维度是“定位层级”。 现有的VLA工具大致可以分为两类:一类是模型训练框架,聚焦于让模型训得更快、更稳、效果更好;另一类是模型集成平台,提供预训练模型库和调用接口,让用户方便地使用已有模型。
FluxVLA Engine不属于这两类。它 向下兼容了训练和集成的功能 ——你当然可以用它训模型、调用模型——但它的 核心定位 在更高或更底层的一层:它是 一套工程体系规范 。
这种定位差异可以用一个比喻来理解。训练框架是“生产汽车的流水线”,集成平台是“汽车展厅”,而FluxVLA Engine想构筑的是让一切汽车真正奔跑起来的“道路系统与交通法规”——确保每一辆车都能在开放路网中读懂彼此意图,有序、高效地协同抵达目的地。
这解释了为什么逐际动力要强调“以公司量级进行资源及长期维护”。做工程基础设施和做一个工具,所需的投入量和持续周期不在一个量级。工具可以迭代几版后进入维护模式,基础设施必须持续演进来适应新的上层需求。
新的模型架构、新的硬件形态、新的部署场景,都需要底座能力随之扩展。
而逐际动力敢于在这个方向上押注, 底气源于多个层面的深厚积累 。
一是真实的工程交付经验。逐际动力不是在实验室里想象行业痛点,而是在大量真机交付项目中反复碰壁后沉淀认知。
从UR机械臂到自研TRON系列机器人,从科研场景到产业应用,这些一线经验让FluxVLA Engine的设计始终锚定在“真实部署”而非“论文指标”上。每一个标准化接口背后,都对应着一个曾经在项目中耗费大量人力的适配环节;每一处模块解耦的设计,都来自于某个“改一行代码影响八个模块”的切身教训。
二是持续的社区生态投入。开源不是把代码扔到GitHub上,而是构建一个能自我生长的开发者生态。
FluxVLA Engine从诞生指出起就在为社区参与设计。模块化的架构天然支持第三方贡献新模型、新数据集适配器、新硬件驱动;统一配置和标准接口让社区贡献可以被轻松集成而非形成分叉。逐际动力计划中的强化学习支持、世界模型模块、3D VLA集成,都不是要“自己做所有事”,而是搭建一个框架,让社区的最新成果能够“插进来就用”。
三是与公司战略的深度绑定。FluxVLA Engine不是逐际动力的一个“副业项目”,而是公司未来生态布局的关键一环。
当这套工程底座被社区广泛采用,越来越多的研究者和开发者基于FluxVLA Engine构建多元模型,平台的生态价值会形成正向飞轮——更好的生态吸引更多用户,更多用户贡献更多模块,更丰富的模块让平台更有吸引力。 这种战略级的投入决心,是一个开源基础设施能否行稳致远的关键变量。
PART 03
修路的人
逐际动力开源FluxVLA Engine,本质上是在做一个选择:与其继续在断裂的工程链路上反复修补,不如重新打下标准化的地基。
修路的人可能不会被聚光灯追逐,但他们定义了车能开到哪里。
对于研究者 ,FluxVLA Engine提供了一个让实验可复现、方法可对比、成果可迁移的公共平台。对于应用开发者 ,它降低了从仿真验证到真机部署的工程门槛,让“跑通一个VLA应用”不再需要一支专业的工程团队。对于整个行业 ,它提供了一套可参考的工程规范,让不同团队的工作能够基于共同的语言和接口展开协作。
当然,一个开源平台的真正生命力,永远取决于社区的参与程度。逐际动力搭好了骨架,而血肉需要由使用它、改进它、贡献它的每一个人来填充。
未来,逐际动力还将通过集成强化学习与世界模型、构建开源社群等手段,推动FluxVLA Engine从工程平台发展为一个开放的具身智能技术生态。
加入FluxVLA Engine开发者社群 :
https://github.com/FluxVLA/FluxVLA/issues/1
GitHub 仓库地址:https://github.com/FluxVLA/FluxVLA
文档与快速上手教程: https://fluxvla.limxdynamics.com/
具身智能的路还很长,而现在,已经有人在认真铺路了。



